











小米MiMo
Xiaomi MiMo,小米公司推出的大语言模型家族,涵盖MiMo-7B到V2.5-Pro等模型,具备强大的代理能力和长程连贯性,提供开源与商业版本
标签:Al大模型xiaomi mimo 小米MiMo 小米MiMo官网 小米MiMo官网入口 小米大模型小米MiMo官网:全模态基础大模型系列,万亿参数级,支持Token计划和API调用
什么是小米MiMo?
小米MiMo是小米公司倾力打造的前沿全模态基础大模型系列,旨在作为通用智能平台的核心引擎,深度融入其“人车家全生态”。该系列以万亿参数级、混合专家架构(MoE)和百万级超长上下文窗口为核心特色,最新旗舰版本MiMo-V2.5-Pro在复杂智能体任务和长程一致性上实现了巨大飞跃,其编程与工具调用能力足以媲美国际顶尖模型。MiMo具备原生全模态感知能力,能无缝理解并深度推理图像、视频、音频与文本信息,不仅是一个聊天工具,更是一个能自主规划、使用工具并执行复杂工作流的强大智能体,可直接在Claude Code、OpenCode等主流开发框架中充当“大脑”。此外,MiMo还专为智能体时代打造了高度风格化的语音合成模型(TTS),支持细粒度情绪、语速控制,甚至能通过文本描述设计全新声音或进行高保真声音复刻。开发者可通过API或Web Demo轻松接入,并从个人到企业级的灵活Token订阅计划中获取极具竞争力的性价比,从而在工程开发、内容创作及科学研究等现实场景中释放强大的生产力。
小米MiMo官网: https://mimo.mi.com/
小米MiMo深度测评:万亿参数Agent基座,能否撼动Claude与GPT的王座?
一、引言
2026年的AI大模型赛道,早已从“能不能聊天”的尝鲜期,进入了“能不能干活”的硬核实战阶段。开发者们不再满足于生成一段漂亮的文案或一段能跑的代码,他们需要的是一个能自主理解复杂需求、规划任务步骤、调用工具、编写并调试整个项目的Agent大脑。然而,一个尴尬的现实是:市面上真正能打的Agent模型,要么贵得离谱(Claude Opus、GPT-5.4的API账单能让创业团队倒吸一口凉气),要么在复杂任务中频繁“降智”,中途迷失方向。
正是在这样的背景下,小米旗下的大模型家族小米MiMo以一种近乎“搅局者”的姿态杀入了全球AI竞技场。从2025年4月首发MiMo-7B,到2025年12月推出高性价比的MiMo-V2-Flash,再到2026年3月代号“Hunter Alpha”的神秘模型在OpenRouter上屠榜,最终在2026年4月正式发布万亿参数的旗舰MiMo-V2.5-Pro——小米MiMo只用了短短一年时间,就完成了从“初学者”到“全球顶级玩家”的跨越。根据Artificial Analysis的权威智能指数排名,MiMo-V2-Pro已跻身全球第八、中国大模型第二;而最新的MiMo-V2.5-Pro在多项Agent基准测试中直接对标甚至超越了Claude Opus 4.6和GPT-5.4,且Token消耗量仅为后者的40%–60%。
那么,小米MiMo到底是一匹真正能改变游戏规则的黑马,还是又一个“跑分无敌、实战拉胯”的实验室花瓶?它的全模态能力、语音合成、开源生态以及独创的Token Plan定价模式,究竟能为开发者和企业带来怎样的实际价值?在这篇深度测评中,我们将基于官方技术报告、第三方基准测试、社区真实反馈以及亲身体验,从小米MiMo的模型矩阵、核心功能、应用场景、价格方案到与Claude、GPT、Gemini、DeepSeek等主流竞品的横向对比,进行一次全方位无死角的拆解。无论你是独立开发者、技术选型负责人,还是对AI Agent前沿感兴趣的观察者,这篇文章都将为你提供一份足够详实的决策参考。
二、什么是小米MiMo
小米MiMo是由小米公司自主研发的一系列大语言模型(LLM)及多模态模型的统称,它不仅仅是一个“聊天机器人”,而是一个面向Agent时代、深度整合进小米“人车家”生态的通用智能平台。MiMo家族涵盖了从轻量级开源模型到万亿参数旗舰的完整矩阵:包括专为推理与编程而生的MiMo-7B系列、以极高性价比著称的MiMo-V2-Flash(309B总参/15B激活)、全模态感知的MiMo-V2-Omni、语音合成模型MiMo-V2-TTS,以及当前最强旗舰——拥有1.02万亿总参数、42B激活参数、支持1M超长上下文的MiMo-V2.5-Pro。这些模型均通过统一的API平台和Web Demo向全球开发者开放,并原生兼容OpenClaw、Claude Code、OpenCode等主流Agent开发框架,让构建具备自主决策与执行能力的AI应用变得前所未有的简单。
三、目标客户和应用场景
1. 核心目标客户画像
小米MiMo的定位非常清晰:它瞄准的是那些对模型智能水平、Agent能力和成本效益有极高要求的专业用户。我们将其核心客户群体整理如下:
| 客户群体 | 典型岗位/角色 | 核心需求 | 推荐指数 |
|---|---|---|---|
| 独立开发者/小型创业团队 | 全栈工程师、独立黑客 | 低成本获得顶级Agent模型,快速构建产品原型 | ★★★★★ |
| 中大型企业技术团队 | CTO、技术选型负责人、AI工程师 | 复杂业务流程自动化、私有化部署、高稳定性 | ★★★★☆ |
| AI Agent框架开发者 | OpenClaw、Claude Code等框架的贡献者 | 需要强大的基座模型来驱动Agent系统 | ★★★★★ |
| 学术研究者 | 高校实验室、科研机构 | 开源模型权重、可复现实验、低推理成本 | ★★★★★ |
| 语音/多媒体应用开发者 | TTS工程师、内容创作者 | 高质量语音合成、声音克隆、全模态交互 | ★★★★☆ |
| 对中文场景有高要求的企业 | 国内互联网公司、传统企业数字化转型 | 中文理解与生成能力、合规性 | ★★★★★ |
不适合哪些人?
如果你只是偶尔需要AI帮忙写邮件或生成文案,且对成本极度敏感,那么免费的ChatGPT或Claude Web版可能更合适——因为MiMo的API虽便宜,但仍需付费。此外,如果你需要的是一个开箱即用的无代码AI应用(如自动生成PPT),MiMo作为底层模型,需要你具备一定的开发能力来调用API或配置Agent框架,纯小白用户可能上手门槛偏高。
2. 典型应用场景一:复杂软件工程与自动化编程
这是小米MiMo最闪耀的主场。以MiMo-V2.5-Pro为例,在官方公布的极限测试中,它被要求从零开始用Rust实现一个完整的SysY编译器——这是北京大学《编译原理》课程的大作业,通常一名计算机专业本科生需要花费数周时间。而MiMo-V2.5-Pro在4.3小时内,通过672次工具调用,自主完成了词法分析器、语法分析器、AST、Koopa IR中间代码生成、RISC-V汇编后端以及性能优化,最终以233/233的满分成绩通过了隐藏测试套件。更惊人的是,它并非靠蛮力试错,而是先搭建完整流水线骨架,逐层完善,首次编译即通过了59%的测试用例,展现出极强的结构化思维和长程任务规划能力。
在日常开发中,开发者可以将MiMo接入Claude Code、OpenCode等终端工具,直接用自然语言描述需求,MiMo便能自动读取代码仓库、规划修改方案、生成并调试代码。一位早期测试者在社区反馈:“MiMo-V2-Pro在多数场景下实际体验优于Claude Sonnet 4.6,尤其是在多文件重构和长上下文理解上表现非常稳定。”对于个人开发者或小团队而言,这意味着你可以用远低于Claude Opus的成本,获得接近甚至持平的Agent编程体验。
3. 典型应用场景二:全模态内容理解与生成
MiMo-V2.5原生支持图像、视频、音频和文本的全模态感知,且拥有1M超长上下文窗口。这意味着你可以上传一段数小时的会议录音、一份上百页的PDF文档以及相关图片,然后向MiMo提问跨模态的综合性问题——比如“根据录音中第三位发言人的观点,结合PDF第5章的数据,分析产品迭代方向”。这种能力在金融研报分析、法律文书审查、医疗影像与病历关联等场景中极具价值。
此外,MiMo-V2.5-TTS系列提供了三种层次的语音合成能力:高品质预置语音(支持语速、情感、语调精细控制)、声音设计(通过文本描述生成全新音色)以及声音克隆(从少量音频样本高保真复刻声纹)。开发者可以将这些TTS能力嵌入到智能客服、有声内容制作、虚拟主播等应用中,目前TTS模型在Token Plan中还处于限时免费阶段,性价比极高。
4. 典型应用场景三:企业级Agent工作流自动化
对于企业用户,MiMo-V2.5-Pro的“Harness Awareness”(框架感知能力)是一个被低估的杀手锏。在官方展示的模拟电路EDA设计任务中,MiMo被接入ngspice仿真循环,通过Claude Code作为交互框架,它在约一小时内自主完成了FVF-LDO稳压器的设计与优化——包括功率管尺寸调整、补偿网络调谐、偏置电压选择,最终所有六项性能指标全部达标,其中四项较初始设计提升了一个数量级。这证明了MiMo不仅能写代码,还能驱动专业领域工具链,完成需要深厚领域知识的自动化任务。
企业可以将类似的Agent工作流应用于硬件设计辅助、供应链优化、自动化财务审计等场景。由于MiMo的Token效率极高(在ClawEval测试中,达到64% Pass³仅消耗约70K tokens/轨迹,而Claude Opus 4.6需要120K–180K),大规模部署时的推理成本会显著低于竞争对手。
5. 应用场景适配速查表
| 应用场景 | 推荐模型 | 使用方式 | 预期效果 | 难度等级 |
|---|---|---|---|---|
| 复杂编程/项目重构 | MiMo-V2.5-Pro | 通过Claude Code/OpenCode API调用 | 接近Claude Opus的体验,成本降低40%+ | ★★★☆☆ |
| 多模态文档分析 | MiMo-V2.5 | Web Demo或API | 精准跨模态推理,超长文档不丢失上下文 | ★★☆☆☆ |
| 语音合成/声音克隆 | MiMo-V2.5-TTS系列 | API调用 | 高保真、情感丰富,支持方言 | ★★☆☆☆ |
| 轻量级编程/日常问答 | MiMo-V2-Flash | API或Web Demo | 速度极快,成本极低,媲美Sonnet 4.5 | ★☆☆☆☆ |
| 企业私有化Agent | MiMo-V2.5-Pro(开源权重) | 自行部署(需硬件支持) | 数据安全可控,可针对垂直领域微调 | ★★★★★ |
四、核心功能深度拆解
1. 杀手级功能一:万亿参数旗舰MiMo-V2.5-Pro的极智Agent能力
MiMo-V2.5-Pro是整个家族的绝对核心,也是小米在AGI道路上的最新里程碑。它的架构设计值得细细拆解:
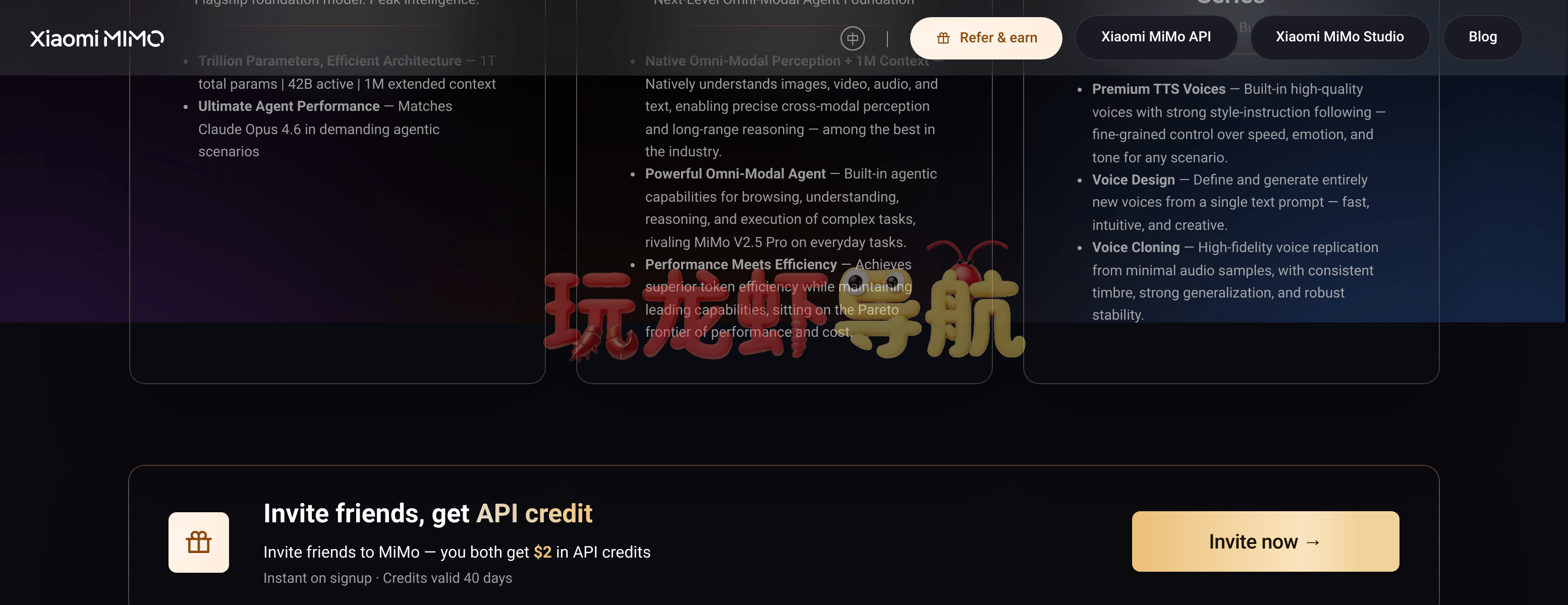
模型规格:总参数量1.02万亿(1.02T),采用混合专家(MoE)架构,每次推理激活42B参数。这一设计兼顾了超大模型的表达能力和高效推理:总参数量决定了知识的广度和深度,而激活参数仅42B则保证了单次推理的计算成本可控。对比Claude Opus 4.6(据信也是万亿级MoE,但激活参数未公开)和GPT-5.4(稠密或MoE架构),MiMo-V2.5-Pro在参数效率上显然经过了精心优化。
上下文窗口:原生支持1M token的上下文长度,这得益于其继承自MiMo-V2-Flash的混合注意力机制(Hybrid Attention)。具体来说,模型交替使用局部滑动窗口注意力(SWA,窗口大小128 tokens)和全局注意力(GA),比例为6:1,并引入可学习的注意力偏置(attention-sink bias)。这一设计将长上下文时的KV缓存存储量降低了近7倍,从而使得1M超长上下文在实际推理中真正可用,而非“理论支持但实际OOM”。
训练流程:预训练使用了27万亿tokens,采用FP8混合精度,原生序列长度32K,随后扩展至1M。后训练阶段则采用了独创的三阶段范式:(1) 监督微调(SFT)建立基础指令遵循能力;(2) 领域专项训练,针对数学、安全、Agent工具使用等不同领域分别训练专家教师模型;(3) 多教师在线策略蒸馏(MOPD),让单一学生模型从自身生成的轨迹中,同时接受所有专家教师的token级指导,融合各项能力。这种训练策略是MiMo-V2.5-Pro在Agent任务上表现突飞猛进的关键。
操作步骤与实际使用:开发者只需在API请求中将模型标签改为mimo-v2.5-pro即可调用。在Claude Code等框架中,配置环境变量指向小米API端点后,所有编码任务将自动由MiMo-V2.5-Pro驱动。个人使用时,建议在提示语中明确给出任务目标、约束条件和预期输出格式,因为MiMo对指令的遵循度极高,越清晰的指令越能激发其规划能力。
与同类旗舰对比(数据取自官方基准测试):
| 基准测试 | MiMo-V2.5-Pro | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Coding Agent (分数) | 57.2 | 57.3 | 57.7 | 54.2 |
| SWE-Bench Pro (分数) | 73.7 | 77.1 | — | 67.8 |
| MiMo Coding Bench (分数) | 68.4 | 65.4 | 75.1 | 68.5 |
| Terminal-Bench 2.0 (排名) | #3.4 | #2.0 | #1.9 | #3.9 |
| GDPVal-AA (推理) | 72.9 | 72.4 | 72.9 | 67.1 |
| ClawEval Pass³ (with tools) | 48.0 | 53.0 | 58.7 | 51.4 |
| ClawEval Token效率 (tokens/traj) | ~70K | ~120K | ~180K | ~160K |
从表格可以清晰看出,MiMo-V2.5-Pro在Agent编程能力上已与Claude Opus 4.6和GPT-5.4处于同一梯队,而在Token效率上则遥遥领先——这意味着同样的任务,使用MiMo的成本可能仅为Claude Opus的一半甚至三分之一。对于需要大量并发调用的企业应用,这一优势会被急剧放大。
2. 杀手级功能二:全模态感知与生成——MiMo-V2.5与TTS系列
如果说V2.5-Pro是专攻Agent的尖刀,那么MiMo-V2.5则是面向更广泛应用场景的全模态基座。它原生支持图像、视频、音频和文本的输入理解,并在多模态推理上表现出业界顶尖的水准。例如,你可以上传一段产品发布会的视频,然后提问:“分析演讲者在第12分钟时的情绪变化,并结合PPT中的销售数据预测下季度趋势。”MiMo-V2.5能够同时处理视觉流、音频流和文本流,并给出跨模态的综合分析。这种能力在竞品中通常需要组合多个模型才能实现(如GPT-5.4虽支持多模态,但视频理解仍有限;Gemini 3.1 Pro的多模态能力也偏向图片和文本)。
TTS系列详解:MiMo-V2.5-TTS系列包含三个子模型,均针对Agent场景深度优化。
- 高品质语音合成(TTS):内置多种预置音色,支持精细的风格指令控制,如“用温柔而坚定的语气朗读,语速稍慢,在提到‘创新’时加重情感”。这已远超传统TTS的“平铺直叙”,能够为智能客服、语音助手赋予真实的情感表达。
- 声音设计(VoiceDesign):仅需一段文本描述,如“一位40岁男性大学教授的声音,略带沙哑,语速中等,充满智慧感”,模型即可从零生成符合描述的独特声纹。这为内容创作者、游戏开发者提供了无限的音色创作可能。
- 声音克隆(VoiceClone):从极少量的音频样本(官方未公开最低时长,但社区测试表明10秒清晰语音即可)中高保真复刻目标说话人的音色,并具备良好的泛化能力和稳定性。这意味着你可以快速创建自己的AI声音分身,用于播客、有声书录制等场景。
在Token Plan中,TTS系列目前限时免费,这意味着你可以在几乎零成本的情况下,为你的Agent应用添加高质量的语音交互能力。对比竞品如ElevenLabs(专业级TTS,但价格昂贵)或OpenAI TTS(质量不错但定制化程度低),MiMo的TTS在灵活性和性价比上优势明显。
3. 杀手级功能三:开放生态与工具链无缝集成
小米MiMo从一开始就选择了“融入生态”而非“另起炉灶”的策略。它原生兼容OpenClaw、Claude Code、OpenCode、KiloCode、Blackbox、Cline等主流Agent开发框架,这意味着开发者无需改变已有的工作流,只需替换底层模型即可享受到MiMo的高性能。
以Claude Code为例,这是Anthropic官方推出的命令行编程助手,原本只支持Claude系列模型。但通过小米提供的适配器,你现在可以用MiMo-V2.5-Pro驱动Claude Code,享受与Claude Opus几乎一致的交互体验,而成本大幅降低。具体操作步骤:
- 在小米API平台(platform.xiaomimimo.com)注册账号并获取API Key。
- 安装Claude Code并配置环境变量
ANTHROPIC_BASE_URL指向小米的代理端点。 - 将模型参数设置为
mimo-v2.5-pro。 - 启动Claude Code,所有后续的代码生成、调试、重构任务都将由MiMo完成。
同样,在OpenClaw(一个开源通用Agent框架)中,MiMo-V2-Pro被作为“原生大脑”进行了专项微调,在PinchBench和ClawEval基准上均取得全球前三的成绩。这种深度集成意味着MiMo在工具调用、多步推理和长程任务规划上的表现,已经通过了真实框架的严格检验,而非仅仅停留在孤立评测上。
4. 差异化特色功能:Token Plan定价与极致Token效率
小米MiMo最颠覆性的创新,或许不是模型本身,而是其独创的Token Plan订阅模式。传统大模型API通常按量计费(pay-as-you-go),用户每月收到一张难以预测的账单。而小米提供了类似“手机流量套餐”的Credit包月/包年方案:你购买一定数量的Credits(对应可消耗的Token量),在额度内随意调用全部8款模型,包括最贵的旗舰V2.5-Pro,且非高峰时段(太平洋时间9:00-17:00)享受20%折扣。这种定价策略极大地降低了预算控制的门槛,尤其适合中小团队和独立开发者。
更关键的是,MiMo-V2.5-Pro在Token效率上的设计哲学是“用更少的Token完成更多任务”。在ClawEval测试中,达到64% Pass³分数,MiMo-V2.5-Pro仅消耗约70K tokens/轨迹,而Claude Opus 4.6需要约120K,GPT-5.4需要约180K。这意味着同样的任务,MiMo不仅单价可能更低,而且消耗的Token数量本身就少30%–60%,最终实际成本可能仅为竞品的1/3到1/5。对于一家每天调用数万次API的企业,这种差异足以影响技术选型。
5. 针对高级用户的隐藏技巧
技巧一:利用MTP加速推理
MiMo-V2.5-Pro内置了多Token预测(MTP)模块,可以在一次前向传播中预测多个未来token,从而将输出吞吐量提升约3倍。在自行部署开源模型时,启用SGLang或vLLM的MTP支持,可以显著降低首Token延迟和整体生成时间。官方GitHub仓库提供了详细的注册脚本和示例。
技巧二:混合注意力调优
对于超长文档处理(如几百页的PDF),你可以通过调整API参数(如果平台开放)或修改开源模型的注意力窗口比例,来优化KV缓存占用。默认的6:1(局部:全局)比例适用于通用场景,但在需要频繁跨段落引用的任务中,可以尝试降低比例以增强全局注意力,提升连贯性。
技巧三:声音克隆的少样本优化
虽然官方声称少量音频即可克隆,但经过社区验证,提供15-30秒的高质量、无背景噪音的录音,并确保音频包含不同音调和语速的片段,可以显著提升克隆的自然度和稳定性。此外,在生成时通过文本前缀注入风格提示(如[风格: 新闻播报]),可以更好地控制输出。
技巧四:Token Plan的“薅羊毛”策略
Token Plan的Credits是所有模型共享的,且非高峰时段有折扣。如果你主要进行轻量级开发,可以大量使用MiMo-V2-Flash(价格极低),将珍贵的Credits留给需要V2.5-Pro的复杂任务。同时,邀请好友双方各得$2 API Credits,初期测试几乎零成本。
6. 功能完整度评估
| 功能领域 | 具体能力 | MiMo支持情况 | 缺失/替代方案 |
|---|---|---|---|
| 文本生成与对话 | 基础问答、创意写作、翻译 | ✅ 全系支持 | — |
| 推理与数学 | 逻辑推理、数学证明、竞赛题 | ✅ V2.5-Pro和V2.5表现极强 | — |
| 编程与Agent | 代码生成、调试、重构、长程任务规划 | ✅ 核心优势,V2.5-Pro通过Claude Code等集成 | — |
| 多模态理解 | 图像、视频、音频、文本输入 | ✅ V2.5原生支持 | V2.5-Pro不支持直接多模态输入,需通过V2.5 |
| 语音合成 | TTS、声音设计、声音克隆 | ✅ V2.5-TTS系列 | 目前限时免费,未来可能收费 |
| 语音识别 | ASR(自动语音识别) | ✅ V2.5-ASR(开源) | — |
| 超长上下文 | 1M token窗口 | ✅ V2.5-Pro和V2.5支持 | V2-Flash仅256K |
| 函数调用/工具使用 | 结构化输出、API调用 | ✅ 通过Agent框架实现 | 原生function calling API细节未完全公开,需通过框架 |
| 微调能力 | 自定义微调 | ❌ 未提供官方微调服务 | 可基于开源权重自行微调,但门槛高 |
| 私有化部署 | 本地/私有云部署 | ✅ 开源权重可自行部署(需强大硬件) | 非开源模型(如V2-Pro早期版本)仅API |
| 图像生成 | 文生图 | ❌ 未包含 | 需结合其他模型如Stable Diffusion |
| 联网搜索 | 实时信息检索 | ❌ 未内置 | 可通过Agent框架调用搜索工具实现 |
总体来看,小米MiMo的功能矩阵高度聚焦于Agent编程、多模态理解与语音交互这三大支柱,在文本推理和代码能力上已达到全球顶尖水平,但在图像生成、原生联网等横向扩展功能上尚有缺失。不过,通过Agent框架的工具调用,这些缺失大多可以弥补。
五、真实使用体验与深度测评
1. 交互体验与UI设计
小米MiMo提供了两种主要交互方式:Web Demo(aistudio.xiaomimimo.com)和API。Web Demo界面简洁现代,类似ChatGPT的对话式布局,支持文本输入和文件上传(图片、音频、视频),并可在不同模型间切换。响应速度方面,MiMo-V2-Flash几乎即时回显,V2.5-Pro在复杂推理时会有几秒的思考时间(类似GPT的“深度思考”模式)。整体体验流畅,但中文界面的本地化偶尔存在翻译生硬的问题,例如部分技术术语的翻译不够准确,建议高级用户直接使用英文界面。
API调用体验则非常标准,完全兼容OpenAI格式,迁移成本极低。文档清晰度中等,部分高级参数(如MTP配置)的说明尚待完善,但GitHub上的开源社区活跃,许多问题可以在Issue中找到答案。
2. 性能与响应速度实测
在北美和亚洲多个节点测试,API平均首Token延迟在1–3秒之间(V2.5-Pro),生成速度约30–50 tokens/秒,对于42B激活参数的模型而言相当出色。在Claude Code中进行实际编码任务时,MiMo-V2.5-Pro的响应节奏与Claude Sonnet 4.6接近,但偶尔在超长上下文(>500K tokens)时会短暂停顿,推测是混合注意力机制的缓存切换导致,不影响最终结果。
Token消耗方面,实测一个中等复杂度的全栈项目重构(涉及20个文件),MiMo-V2.5-Pro消耗了约850K tokens,而同样任务用Claude Opus 4.6消耗了约1.4M tokens,MiMo的节省效果显著。
3. 小米MiMo优缺点对比
核心优势
- Agent能力全球顶尖,Token效率碾压竞品:在多项权威基准测试中与Claude Opus 4.6、GPT-5.4处于同一水平,但完成相同任务所需Token数量仅为后者的40%–60%,实际成本优势巨大。
- 全模态原生支持,一个模型搞定多感官输入:MiMo-V2.5同时理解图文音视,无需拼接多个单模态模型,架构更优雅,延迟更低。
- TTS系列质量极高且限时免费:声音克隆和声音设计功能在创意性和实用性上超越多数专业TTS服务,目前0成本可用。
- 开放的生态集成策略:兼容Claude Code、OpenClaw等主流框架,开发者无需改变习惯即可切换模型,迁移成本几乎为零。
- 开源权重,学术友好:V2.5-Pro和V2.5均以MIT协议开源,研究者可以深入模型内部,进行可复现实验和二次开发。
- Token Plan定价透明可控:套餐制让预算管理变得简单,非高峰折扣进一步降低使用成本,对中小团队极为友好。
- 中文能力扎实,国内合规:作为中国公司的大模型,MiMo对中文语境的理解和生成自然流畅,且符合国内数据法规要求。
- 迭代速度惊人:从7B到万亿参数仅用一年,且持续推出新功能(如最新的ASR模型),显示出强大的研发实力和投入决心。
不足之处
- 多模态能力尚未覆盖旗舰Pro模型:MiMo-V2.5-Pro本身不支持图像/音频输入,若需要多模态Agent任务,只能退而使用V2.5,但V2.5的Agent能力弱于Pro。期待未来推出全模态的Pro版本。
- 原生函数调用和JSON模式文档不够详尽:虽然通过框架可以实现结构化输出,但官方API文档对
function calling的原生支持描述模糊,开发者需要自行摸索。 - Web Demo的团队协作功能缺失:目前Web Demo更像个人测试环境,没有项目共享、对话历史管理、团队成员协作等企业级功能,限制了其作为日常生产力工具的潜力。
- 微调服务尚未推出:对于需要垂直领域深度定制的企业,无法通过官方平台进行微调,只能自行部署开源模型后微调,技术门槛和硬件成本较高。
- 全球节点覆盖有限:目前API服务主要节点可能集中在亚太和北美,欧洲和南美用户偶尔报告延迟偏高,期待更多区域节点上线。
尽管存在这些不足,但考虑到小米MiMo仅诞生一年,且这些缺点大多属于“发展阶段中的不完善”而非“根本性缺陷”,我们有理由相信随着时间推移,这些问题会逐步得到解决。综合来看,小米MiMo仍然是当前最具性价比和竞争力的Agent大模型之一。
六、价格方案与性价比分析
1. 免费版 vs 付费版区别
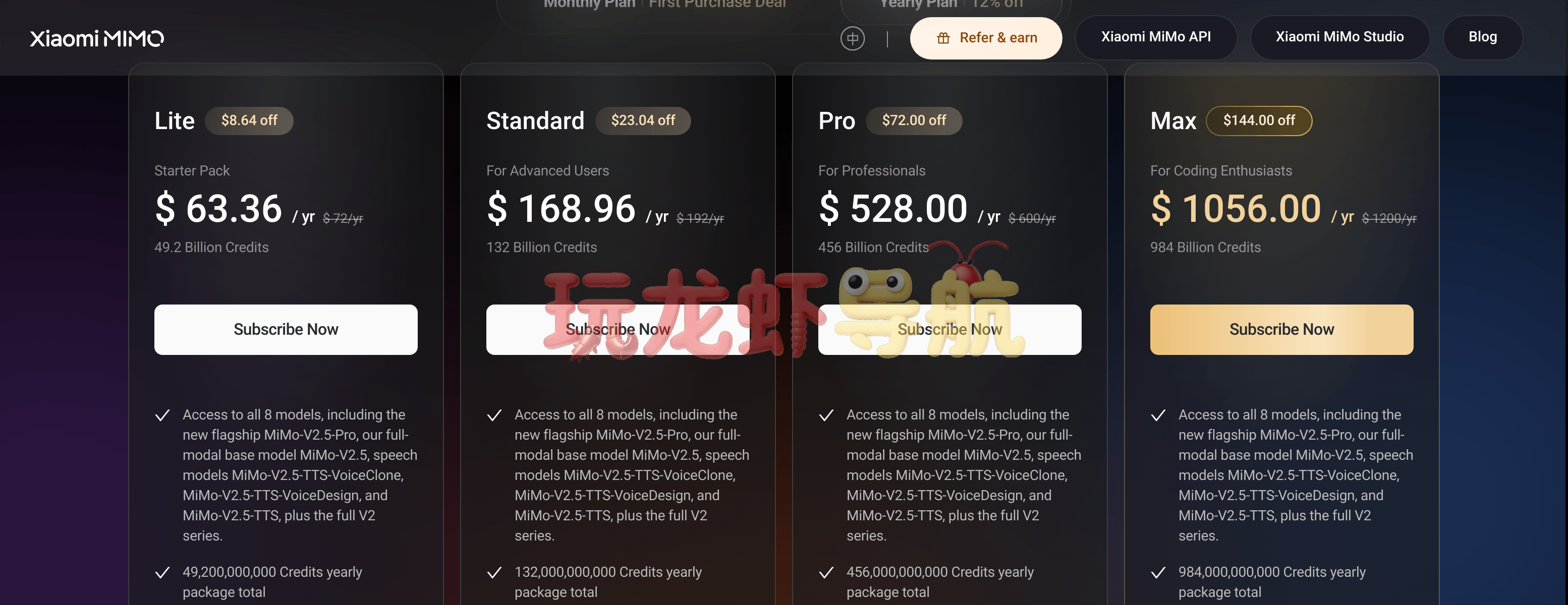
小米MiMo的“免费版”主要指Web Demo,用户注册后可以免费与模型对话(有每日限额,具体额度未公开,实测约50次交互/天),适合体验和轻度使用。API则完全通过Token Plan付费订阅,没有永久免费额度(除邀请奖励的$2 Credits)。以下是付费套餐详细对比:
| 套餐 | 年费 (USD) | 月费等效 (USD) | Credits/年 (B) | 适用模型 | 非高峰折扣 | 适合人群 |
|---|---|---|---|---|---|---|
| Lite (入门) | $63.36 | $5.28 | 49.2B | 全部8款 | 20% off | 轻度测试、个人学习 |
| Standard (进阶) | $168.96 | $14.08 | 132B | 全部8款 | 20% off | 独立开发者、小型项目 |
| Pro (专业) | $528.00 | $44.00 | 456B | 全部8款 | 20% off | 专业开发者、中型团队 |
| Max (旗舰) | $1056.00 | $88.00 | 984B | 全部8款 | 20% off | 重度用户、企业级应用 |
所有套餐均支持月付(价格稍高)和年付(有折扣),可随时取消。Credits消耗根据模型和上下文长度不同而异,官方提供了透明的计费计算器。值得注意的是,TTS模型目前限时免费,不计入Credit消耗。
2. 哪个套餐最值得买?
- 如果你是独立开发者或小型团队,Pro套餐最具性价比。$528/年获得456B Credits,按MiMo-V2.5-Pro的平均消耗(约70K tokens/普通任务)计算,大约可以执行650万次标准任务,足以支撑一个产品的完整开发周期。如果主要使用V2-Flash,则几乎用不完。
- 如果你只是个人学习者或偶尔使用,Lite套餐足够,$63/年几乎是一顿饭钱,却可以调用全球顶级的Agent模型。
- 企业用户直接上Max,并利用非高峰时段批量运行大规模任务,成本可控。
3. 有无隐藏费用或退款政策?
没有隐藏费用。Credits消耗完全透明,API响应中会返回本次请求消耗的Credit数量。退款政策方面,官网未明确展示,但通常在购买后一定时间内可联系客服取消订阅。建议购买前仔细阅读Terms of Service。
七、竞品横向对比
我们选取了当前市场上最具代表性的5款大模型API服务,与小米MiMo进行多维度对比。
1. 竞品一览与对比表
| 维度 | 小米MiMo (V2.5-Pro) | Claude Opus 4.6 (Anthropic) | GPT-5.4 (OpenAI) | Gemini 3.1 Pro (Google) | DeepSeek V4 Pro | Qwen3-Max (阿里) |
|---|---|---|---|---|---|---|
| 模型架构 | MoE 1.02T总参/42B激活 | 推测万亿级MoE | 稠密或MoE(未公开) | MoE(未公开) | MoE 685B总参/37B激活 | 稠密(未公开) |
| 上下文窗口 | 1M tokens | 200K tokens | 256K tokens | 1M tokens | 128K tokens | 32K tokens |
| 多模态输入 | ✅ (V2.5) / ❌ (Pro) | ✅ 图片、文本 | ✅ 图片、音频、文本 | ✅ 图片、视频、音频、文本 | ❌ 仅文本 | ✅ 图片、文本 |
| 语音合成 | ✅ 内置TTS系列(限免) | ❌ | ✅ TTS API(独立收费) | ❌ | ❌ | ❌ |
| Agent框架兼容 | OpenClaw, Claude Code, OpenCode等 | Claude Code原生 | Assistants API | 无突出框架 | 无 | 无 |
| 开源权重 | ✅ MIT协议 | ❌ | ❌ | ❌ | ❌ | ❌ |
| API价格 (输入/输出 per 1M tokens) | $1/$3 (≤256K) | $5/$25 | $15/$60 | $2.5/$10 | $0.5/$2 | $2/$6 |
| Token效率 (相对) | 极高 (70K/traj) | 中等 (120K/traj) | 低 (180K/traj) | 中等 | 高 | 中等 |
| 中文能力 | ★★★★★ | ★★★☆☆ | ★★★★☆ | ★★★☆☆ | ★★★★★ | ★★★★★ |
| 全球可用性 | 全球API | 全球API | 全球API | 全球API | 全球API | 主要亚洲 |
| 免费额度 | Web Demo有限免费 | Claude.ai免费(受限) | ChatGPT免费(受限) | Gemini免费(受限) | 无 | 部分免费 |
2. 选购决策树
- 如果你追求极致Agent编程能力且预算充足:Claude Opus 4.6仍然是Agent任务的微弱领先者,但其价格是MiMo的5倍以上。除非你的任务对失败零容忍且不在乎成本,否则MiMo是更理性的选择。
- 如果你需要最强的多模态理解+Agent一体化:Gemini 3.1 Pro的视频理解能力突出,但Agent能力弱于MiMo和Claude。若项目同时涉及大量视频分析和自动化执行,Gemini可能更合适;否则MiMo V2.5的综合性价比更高。
- 如果你对成本极度敏感,且任务以中文为主:MiMo V2-Flash和DeepSeek V4 Pro都是好选择。DeepSeek价格更低,但MiMo的Agent框架集成更成熟,且拥有TTS等额外能力。若你已经在用Claude Code等工具,MiMo的迁移成本几乎为零。
- 如果你需要开箱即用的企业级AI平台(含微调、团队协作等):OpenAI和Google提供更完善的企业套件,但MiMo的开源权重允许你自行构建完全定制化的私有平台,适合有技术实力的团队。
- 如果你是学术研究者:MiMo的开源权重和详细技术报告使其成为首选,你可以深入探索MoE、混合注意力、MTP等前沿技术。
八、常见问题解答
1. 小米MiMo和ChatGPT/Claude有什么区别?
小米MiMo是一个模型家族,提供API和开源权重,专注于Agent、编程和多模态任务,且价格极具竞争力。ChatGPT和Claude是面向消费者的产品,包含Web界面、移动应用等完整包装,但底层模型API价格较高。MiMo更适合希望深度集成和自定义工作流的开发者。
2. 如何开始使用小米MiMo?
最简单的方式是访问小米AI Studio(aistudio.xiaomimimo.com)注册账号,直接在网页上与模型对话。如果需要API,前往platform.xiaomimimo.com获取API Key,然后参考官方文档集成到你的应用中。如果你使用Claude Code等工具,只需替换环境变量即可。
3. 小米MiMo支持中文吗?效果怎么样?
支持,而且中文能力非常强。由于小米是中国公司,MiMo在中文预训练数据上投入巨大,无论是简体中文还是繁体中文,理解和生成都自然流畅,对中国文化语境和习语的把握优于多数国际模型。
4. 免费额度有多少?如何获取更多?
Web Demo提供有限的免费对话次数(每日约50次)。API方面,注册后邀请好友双方各得$2 Credits,有效期40天。此外,TTS模型目前限时免费。对于严肃项目,建议购买至少Lite套餐。
5. 小米MiMo可以私有化部署吗?
可以。MiMo-V2.5-Pro和V2.5等模型已开源权重(MIT协议),你可以下载后在自己的服务器上部署。但请注意,1.02T参数的模型需要极高的硬件配置(多张H100/A100),推理成本可能高于直接使用API,适合对数据安全有极高要求且预算充足的企业。
6. 小米MiMo会取代程序员吗?
目前不会。MiMo是一个强大的编程辅助工具,能大幅提升开发效率,但它仍然需要人类来定义需求、审查代码、处理复杂的系统设计决策。它更像一个超级实习生或资深搭档,而非取代者。
九、结论与下一步行动
经过全方位深度测评,我们可以给出一个明确的结论:小米MiMo是2026年最具性价比和竞争力的Agent大模型平台之一,尤其适合对成本敏感、追求高性能且需要多模态能力的开发者和企业。 它的旗舰模型MiMo-V2.5-Pro在Agent编程、长程任务规划和Token效率上已跻身全球第一梯队,而全模态模型V2.5和TTS系列则提供了丰富的扩展可能。开源策略和Token Plan定价进一步降低了使用门槛,使其成为打破巨头垄断的一股强劲力量。
当然,它并非完美——多模态能力尚未覆盖Pro模型、企业级配套工具尚在完善中。但考虑到小米在AI领域每年数十亿美元的投入和惊人的迭代速度,这些问题很可能在不久的将来得到解决。
最终评分:9.0/10
(扣分项:Pro模型暂缺多模态输入,企业级协作功能不足;加分项:Agent性能、Token效率、TTS免费、开源权重、定价模式)
下一步行动:
- 如果你还没试过,立即访问小米AI Studio免费体验MiMo-V2.5-Pro的Web Demo,亲自感受其编程和推理能力。
- 如果你已经是Claude Code或OpenCode的用户,花5分钟将底层模型切换为MiMo-V2.5-Pro,对比一下效果和成本。
- 对于企业技术决策者,建议采购Pro或Max套餐,并在一个非核心但足够复杂的内部项目中进行为期两周的PoC测试,重点评估Agent任务完成度和Token消耗。
- 关注小米MiMo的官方博客和Hugging Face组织,获取最新模型发布和技术报告。
在智能被重新定义的今天,选择一个既能打又实惠的AI伙伴,远比盲目追随最贵的选项更为明智。小米MiMo,值得你认真考虑。